ChatGPT Scrapes Google and Leaks Prompts
Categories: ai
UPDATE: Thanks to Ars Technica’s reporting on this story, OpenAI has claimed to have fixed the leakage but that this only affected a “small number” of prompts.
Based upon what OpenAI has said and the speed of the response I think it’s most likely that the glitch was related to the layer of ChatGPT that turns search prompts into actual web searches. In other words, asking ChatGPT “Tell me an analytics company in ohio owned by Jason Packer” should turn that into a web search for “ohio analytics company jason packer” or something like that. I think that layer was not working or being skipped in some cases and the raw prompt was being searched for. It’s quite likely ChatGPT is still scraping Google, just they have fixed the bug that caused full prompts to be directly leaked. That’s an important fix, but limited.
Whether it’s the new masters of the internet like OpenAI and Anthropic, or the old masters like Google or Microsoft operating under a new playbook — the internet doesn’t work like it used to. That’s not inherently bad, but let’s not forget the second part of “move fast and break things” involves breaking things. It’s a five-word phrase so you’d think remembering all five should be very doable… but that’s where we’re at. We should consider that in 2025, the “things” that get broken are a lot more critical to people’s lives than in the old days of the internet.
In the latest edition of this, here’s a reminder that prompts aren’t as private as you think they are!
A friend of mine noticed some weird searches showing up in her Google Search Console. Things that had nothing to do with her site and seemed like ChatGPT prompts. Eventually I was able to replicate this same behavior in my GSC as well.
Check it out: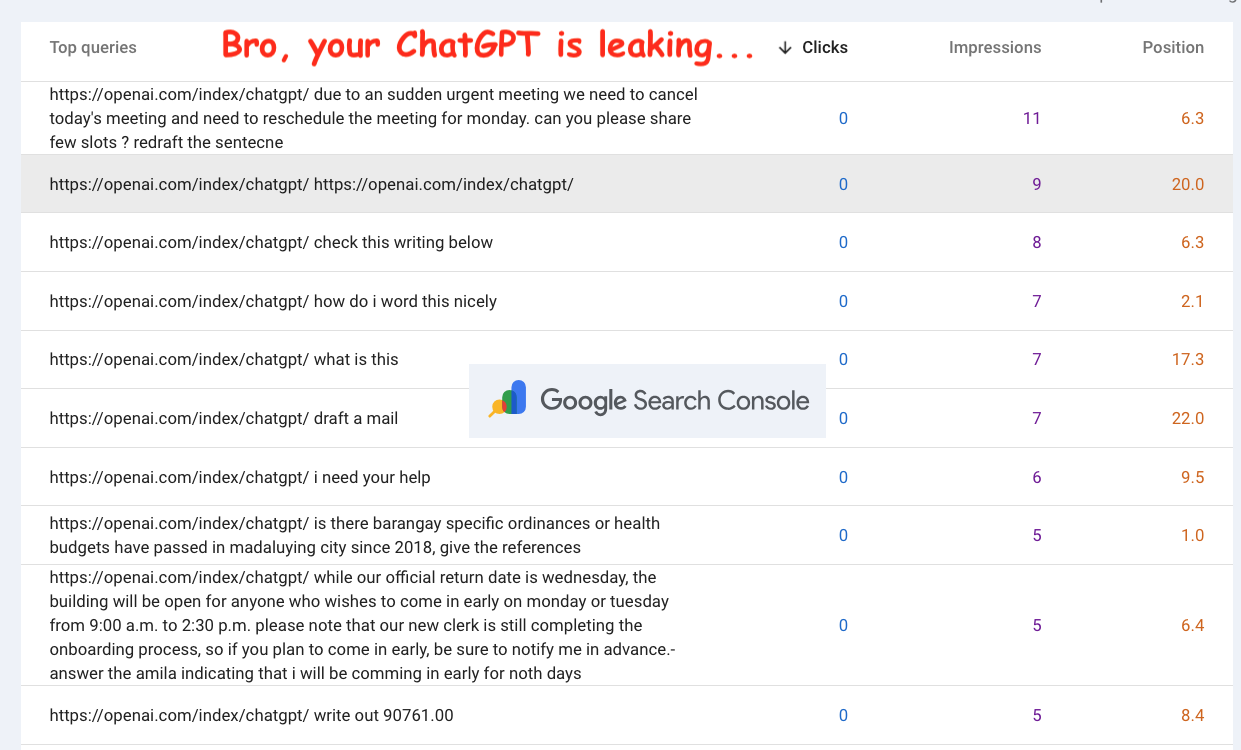
We found hundreds of different prompts so far, including this quite personal stuff that I feel a bit guilty about sharing but is necessary to show what kind of details can get leaked:

Wew. But what the heck? How is ChatGPT leaking into Google Search Console?
With the help of fellow internet sleuth Slobodan Manić we figured it out.
It’s because these sites rank well in Google Search for the search:
https://openai.com/index/chatgpt/
Both my friend and I have written multiple articles about ChatGPT (let’s face it who hasn’t at this point). In particular an article about ChatGPT prompts getting indexed by Google, which is pretty ironic. You don’t even have to use that exact URL (https://openai.com/index/chatgpt/) on the page. Just something that Google’s tokenization turns into openai + index + chatgpt.
Don’t get confused though, this is a new & completely different ChatGPT screw-up than having Google index stuff we don’t want them to. Weirder, if perhaps not as serious.
It’s been known for a few months now that OpenAI directly scrapes Google Search. This article is more proof of that questionable behavior. In fact as far as we’re aware this is the first definitive proof that OpenAI directly scrapes Google Search with actual user prompts. Not just that OpenAI is scraping SERPs in general to acquire data, but that user prompts are getting sent to Google Search.
Why does OpenAI scrape Google? They already have agreements with Microsoft to get search data the proper way from Bing via API. APIs are safer, faster, and much more efficient than scraping — but OpenAI is just that hungry for every byte of data out there. While Google Search results do appear in other mets search engines like Kagi, Google Search data is not something Google easily gives away. Did Google not want to allow access to OpenAI for competitive reasons? Would OpenAI not meet their price? Who knows, but whatever the reason OpenAI said “screw it, let’s just scrape them”.
The choice to scrape instead of using a private API means prompts from OpenAI that use Google Search show up in users’ Search Console data. Did OpenAI go so fast that they didn’t consider the privacy implications of this, or did they just not care?
The ChatGPT prompt box on that particular page: https://openai.com/index/chatgpt/
has a bug in it which causes the URL of that page to be added to the prompt. So whatever you put in there gets the URL prepended to your prompt. E.g.:
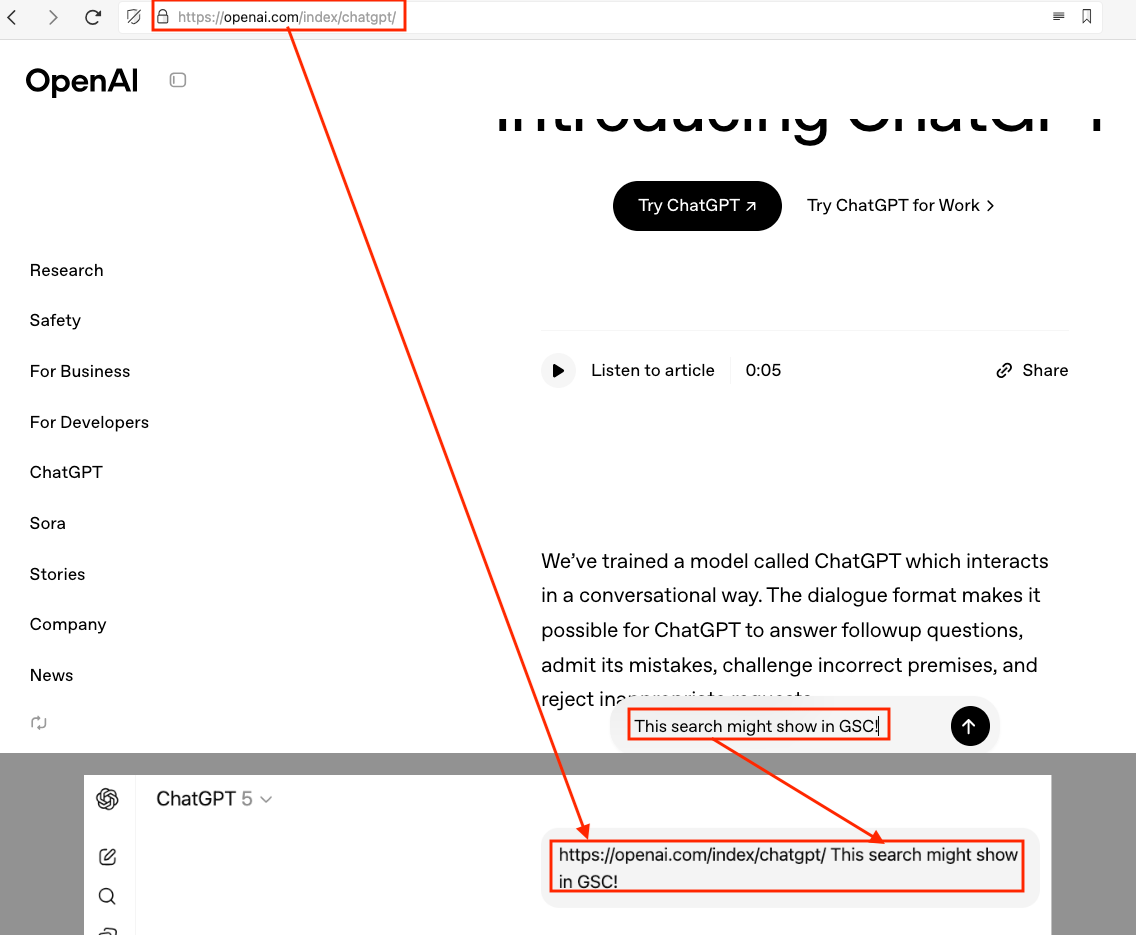
So whatever you say gets that “https://openai.com/index/chatgpt/” text added to the front of it.
Normally ChatGPT 5 will choose to do a web search whenever it thinks it needs to, and is more likely to do that with an esoteric or recency-requiring search. But this bugged prompt box also contains the query parameter “hints=search” to cause it to basically always do a search:
https://chatgpt.com/?hints=search&openaicom_referred=true&model=gpt-5
But we know it MUST have used Google Search for those searches to show in GSC logs, and doubly we know it must have scraped those rather than using an API or some kind of private connection — because those other options don’t show inside GSC. Meaning that OpenAI is sharing any prompt that requires a Google Search with both Google and whoever is doing their scraping. And then also with whoever’s site shows up in the search results! Yikes.
To be clear, this data leakage can happen with ALL ChatGPT prompts that use Google Search… It’s just this particular odd set of circumstances that shows the leak in action.
Ok, to recap, here’s the steps required for this wackiness to ensue:
Step 1: Posts that include the right content to show up for a Google Search on [ https://openai.com/index/chatgpt/ ]
Step 2: A ChatGPT prompt that calls Google Search and returns the site. In addition to the buggy prompt box that Slobodan discovered, there’s other ways this could happen too. I originally thought this was probably from users putting their ChatGPT prompts into the Chrome address bar. While you should never underestimate users’ ability to break whatever UI you put in front of them, that’s probably not what’s happening.
Step 3: This prompt shows up in Google Search Console as a search impression!
If this kind of leakage can happen accidentally, it’s worrying to think about cases with people actively trying to exfiltrate user prompts!
Especially with the latest release of OpenAI’s Atlas browser, we have to remember that user privacy and “playing by the rules” are not a part of big AI’s playbook. Whether its chats getting indexed by Google, LLM bots scraping anything not tied down, web searches being leaked into GSC, or your entire ChatGPT history being stored indefinitely (but only temporarily, if that makes any sense at all!) — this is a new set of norms and standards being worked out real-time in some of the most chaotic conditions possible.
Since this article is getting a lot of attention, here’s a quick FAQ:
Q: How do I see this in my own Google Search Console data?
A: You are extremely unlikely to. You need to ranked well for the keyword “https://openai.com/index/chatgpt/”, which your site probably does not. You could be getting other keyword data from ChatGPT’s scraping but there’s no way to distinguish it from regular Google Search.
Q: How do you know this is OpenAI scraping, and not a regular Google Search or some weird bot traffic?
A: We don’t 100%, but with the previous reporting on ChatGPT scraping Google + the incredible coincidence of that particular page pre-pending the URL to the prompt + content of the prompts themselves this is the clear logical explanation.
Q: Does this only happen with queries from that one page (https://openai.com/index/chatgpt/) with the bugged prompt?
A: We believe the scraping happens widely. It’s unclear if the prompt leak is widespread or related to that particular page.
Q: Why is this a privacy issue at all, isn’t this the same as regular Google Searches ending up in GSC?
A: As you can see from the examples above, chatbot prompts are different and much more conversational than standard keyword searches. GSC’s keyword disclosure privacy guardrails are (presumably) based upon sanitizing Google Search data, not chatbot prompts. This data ends up not just in GSC but in Google Trends and potentially other places. Ultimately we shouldn’t expect prompts that we give to OpenAI to end up in the Google ecosystem under different privacy controls.
No comments yet.