How Many Users Block Google Analytics, Measured in Google Analytics
Categories: analytics
December 2017 update (blocking levels down some).
June 2016 update (blocking levels a little higher).
There’s now a significant number of users that use ad-blockers, estimated at about 15% in the US (according to PageFair), and that number grew quickly in 2015. Extensions like AdBlock Plus, NoScript, and Ghostery are incredibly popular (#1, #4, and #6 amongst the most popular Firefox add-ons), and for good reasons. The ad-blocking “war” has been a very hot topic of conversion, so I wanted to take a look at some of the collateral damage in that war — blocked analytics trackers.
Ad Blockers That Block Analytics
Since ad blockers are focused on blocking ads (shocking, I know…) we might not think about their effects on our analytics trackers. But did you know that most of the popular blockers can block analytics trackers as well? Some even do it by default. There are a lot of different ad-blockers out there on a lot of different platforms, but a quick run through the most popular per platform shows a huge number of users that could be blocking our analytics trackers. I’m focusing on Google Analytics here, but really this is applicable for any third-party tracker. Here’s a list of some of the top blockers (and there are a lot more out there!):
| App / Extension | Platform | Users (Dec 2015) | Users (Dec 2017) | Blocks GA by default? |
| AdBlock Plus | Cross-platform | 21M users (Firefox) 40M+ (Chrome) 300M total downloads |
13.2M users (Firefox) 100M+ users (total) 500M+ total downloads |
No, but easily added (one click post-install) |
| Adblock | primarily Chrome | 40M+ (Chrome) | 40M+ (total) | No, but easily added. |
| uBlock Origin | Cross-platform | 630k users (Firefox) 2.5M users (Chrome) |
4.2M users (Firefox) 10M+ users (Chrome) |
Yes |
| Ghostery | Cross-platform | 1.5M users (Firefox) 2.3M users (Chrome) |
1M users (Firefox) 2.9M users (Chrome) |
No, but easily added. |
| Purify | iOS | unknown, top 10 at launch* | #363 in App Store (via Applyzer) | Yes |
| Adblock (FutureMind) | iOS | – | #39 in App Store | No, but easily added. |
| Adblock Browser (Eyeo) | Android | 1-5M installs | 10-50M installs | Depending on install options |
| Google Analytics Opt-Out | Chrome | 720k users | 760k users | Yes |
* Post-iOS9 launch blockers Peace, Purify & Crystal were #1, #3 & #6 respectively in the App Store.
(Browser add-on active users are based on users that are actively check for updates, seemingly regardless of add-on status. This means users that have the add-on disabled would still be counted. However most users do not disable, Firefox reports 95% of uBlock Origin users and 96% of AdBlock Plus users did have their add-ons set to enabled according to their add-on status information page).
Who even needs a plugin? As of November Firefox includes tracking blocking protection in the browser itself, on by default and blocking GA in private browsing windows.
That’s a significant potential for gaps in our measurements, but how many users exactly?? The biggest user base is the AdBlock Plus users, but it is hard to know how many of those users choose to block analytics trackers. When you install AdBlock Plus you get a post-install screen that gives you a choice to turn on tracking / analytics blocking:
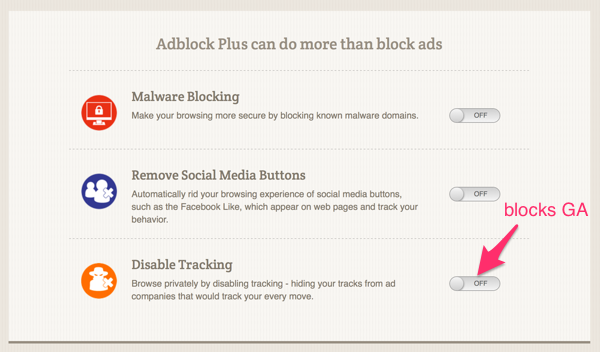
AdBlock Plus Post-Install Screen
We know that most users stick with the defaults (which does not block GA), but considering the size of the install base that is probably a number big enough to be concerned about. If you are a user that is motivated / annoyed enough to install an ad blocker you are already in the group much less likely to stick with defaults.
Measuring the amount of users that run ad-blockers in general can be a little tricky, but the primary method is pretty well established at this point. You create content that looks like an ad on your site and then see if is being blocked by looking at what is ultimately loaded by the browser. Daniel Carlbom has an easy-to-implement ad-blocker user counting method on his blog using Google Tag Manger, or PageFair also offers a free service that will track your ad-block percentage with a sensor you place on your site.
Except what happens if your analytics service is also being blocked?! Both GA and PageFair are in the Ghostery and AdBlock Plus list of analytics trackers to be blocked. This means these methods are measuring users that block ads but do allow analytics trackers, so your actual ad-block percentages are even higher than these methods show.
So what do we do? How do we measure things when its our measurement software itself that’s being blocked! Should we all just go back to server log file analyzers!?
After breathing into a bag for a while, I decided to try a small experiment to see if I could get at least a general idea of how many people are blocking Google Analytics.
An Experiment to Count the Blockers
My approach was to run GA in parallel, once as normal in the browser, and then once using the GA measurement protocol on the server-side. So every request would result in firing two different events; one client-side through analytics.js, and one server-side via the measurement protocol API:

Parallel GA measurement
This has the effect of double-counting everything, an event call from the front-end along with an event call from the back-end with all the relevant front-end info passed to it.
I just needed a way to line up the two event hits, so I’d know it was the same end-user making both requests. Enter browser fingerprinting. I expect many of you are familiar with browser fingerprinting; it is a way to assign a (relatively) unique id to each user’s browser based on the configuration and settings of that browser (first brought into wide discussion from the EFF’s Panopticlick project). I used fingerprint2.js to create the fingerprints, which uses 24 different sources of settings to assign a unique id per browser. It is certainly possible to end up with the same fingerprint for two different end-users, but it’s rare and in our case is not likely to influence our overall numbers since it would simply take one data point away.
(I could have achieved a similar effect with a random id that I created and then dropped as a cookie, but I chose to use a fingerprint because using cookies to track users that run blockers might have lead to a small number of users that aggressively clean their cookies getting counted a bunch of times. It also leads to less duplication in the case of bots that might purge their cookies frequently. In general I do not recommend use of fingerprinting as a tracking mechanism as it can be overly invasive.)
The end result is lots and lots of duplicate events:

Raw GA calls from analytics.js and measurement protocol mashed up.
What you’ll (hopefully) notice is that every event comes in a pair in the list above aside from one. So what happened there? This happened:

Client-side GA measurement blocked
Meaning something happened to block the analytics.js code from reporting to GA, which is exactly what we want to measure! In the example above I know for sure what happened because that one was me testing — using Ghostery to block GA.
So we can just count up all the cases where we got a call from the server-side, but not the client-side, right?
Well… almost. There are a couple of special cases that we need to look at first.
1. Bots.
Yea, bots… The unsleeping, unrelenting bane of any web analyst looking to get precise numbers.The first bit of good news is that our method is JavaScript-heavy, meaning we’ve knocked out many bots already. Before the server-side PHP script calls the measurement protocol it had to jump through these JS-hoops: a) successfully be fingerprinted via JavaScript and b) do a jQuery AJAX call.
This means the only bots we’re left with are the very capable “headless browsers”. This is a growing percentage of bots, but still likely in the single digits (Incapsula reported only 1.2% of DDoS bots were capable of passing JavaScript+cookie challenges in Q3 2015). Of particular concern are ones that end up as false positives (i.e. bots that only fire the server-side code not the client-side code) and/or show up under multiple fingerprints, thus getting counted multiple times.
Interestingly in this experiment the main offender of this was Googlebot. It is of course capable of doing all the JavaScript required, but it is also smart enough to know not to fire the GA tracking code on the client-side. It even came in under multiple browser fingerprints (which is very interesting in its own right). Other search engine bots like Baidu also showed up for me in this way; capable enough to render all the JavaScript but “compassionate” enough to not fire client-side Google Analytics sensors. Excluding these bots was actually really easy, it was just a question of clicking the exclude bots box in the view configuration. You know, this guy under view settings:

Unfortunately there were other bots as well. Filtering out the referral spam bots was easy enough just using my referral spam filter. I excluded some other bots as well based on manual inspection of their behavior and network source. Some bots will fire GA just like an other JavaScript and some won’t, once you exclude any that create a lot of different browser signatures it hopefully should not have a big impact on our data.
2. Callback failures.
Ok, I admit it, that chart above is not entirely correct. There’s still another way we can get only the server-side measurement call:

Server-side return code not executed (browser disappeared?)
If the AJAX call is made but the browser disappears before the callback happens, then we can also miss out on the client-side call. Or if the browser just doesn’t execute the callback code itself we will get mismatch.
Because the fingerprint generation is relatively slow (about 500ms for me the first time it runs) and the AJAX call doesn’t happen until that succeeds and is relatively fast (~200ms depending on latency), the browser would need to disappear at just the right time (in between when the AJAX call was made and when it returns) to miss the callback. This could happen if you hit the back button at just the right time. To verify that this wasn’t a major issue I ran a test looking at sessions with > 1 event. This means the user hit more than one page, which solves the back button issue, though potentially not other technical callback issues. The result was nearly the same rate of blocking users, just a much smaller sample size, which convinced me to ignore this possible effect.
Ok, finally time to count up the results. There’s no way inside the regular GA reporting system itself to do that kind of comparison on individual sessions, but it’s easy to do in R, so let’s make a venn diagram!

red: server-side, blue: client-side, purple: both
The red is only server-side measured, blue is only client-side, and purple is measured by both. The blue (client-side only) sliver is so small (.34%) it’s hard to see, but that’s what we should expect. It should be exceedingly rare in our scenario that the client-side fired ok when the server didn’t. This might happen if there was a PHP error on the server-side or the measurement protocol hit was never registered for whatever reason. At .34% I’m not going to worry too much about that. The server-side only slice is very big though, over 8%!
That a pretty high number, definitely higher than I was expecting. Let’s do some sanity checks. Based on what we know about ad-blocking popularity and how the tools work I’d expect the following (for the record, I came up with this list before processing the results):
- Higher percentage of blocking in the EU vs. US.


- Higher percentage of blocking on desktop vs. mobile.


- Higher on iOS vs Android.


- More Firefox, less IE.


So a confirmation on all our assumptions! Could it really be so high, 8.7% missed?
First off, the site I used for testing is one that is solidly in the demographic for running blockers: young (50% 18-34), male (68%), and internet savvy (the #1 page on the site is internet meme-related). These demographics have potentially very high levels of blocking. A survey from Moz + Fractl found 63% of respondents in that 18-34 demographic said they used ad blockers, though most actively measured (rather than surveyed) numbers have been much lower. If for example the true ad blocker percentage on our test site was 25% it doesn’t seem unreasonable to me that 1/3 of those people were also blocking analytics trackers.
Second, there is still the issue of bots & callback failures. A certain amount of callback failures may happen, though I’m unable to estimate how many exactly. In my browser testing the callback method was 100% reliable, but in the wild it is likely to be imperfect.
Takeaways
Overall this is a somewhat limited experiment on a single niche site (about 2,400 users measured over a month), but it was enough to convince me that there could be quite a few users disappearing from our third party analytics. For increased accuracy I would like to run the experiment again on a site with more traffic, a more average demographic, and more comprehensive bot detection.
Most of us analysts rely on these numbers so much that it’s difficult to consider the ways in which they are wrong or incomplete. For example when I first pulled the demographic stats from GA on the standard profile for the experiment site I was not even considering that it would not include our blockers, which would likely skew the demographic numbers even more. Just as spam bots distort our stats in a way we can see, the missing real users distort without us knowing they are even missing.
This discussion is also connected back to “Do Not Track” preferences as well. In a previous experiment on DNT preferences (run on a different site) I found about 17% of users had opted into a DNT On setting (again, only counting those that don’t block GA!). If those 17% weren’t getting their preference respected, then who can blame them for wanting to install a blocker? How do we respect a preference for not being tracked while still knowing enough about the existence of those users to run our sites effectively? Definitely a discussion that is worth happening, but while we are just starting that discussions many users have clearly already taken action as I think this experiment shows.
Since originally publishing this article in January I’ve continued to collect data. Here’s the update, this follow-up is based on 8,400 samples, so about 3.5x larger than our first experiment.
Update June 2016
Total GA blockers are up: from 8.7% (Dec-Jan) to 11% (Jan-Jun).

Again, it is very important to note this is for our test site, which has a demographic with a higher adblock % than typical, the average site is very likely much lower.
Where did that growth (+2.3%) come from?
- More ad-blocker users overall (ad-blocker adoption continues to grow in 2016).
- An increase particularly in Android blockers
- Our original sample had substantially more iOS blockers than Android:
- In our new sample Android has caught up in blocker usage, in fact becoming slightly more likely to use blockers than iOS:


- Our original sample had substantially more iOS blockers than Android:
The reason for this change is that as of Feb 1 Samsung started allowing ad blocking via their browser and plugins so apps like Crystal Adblock that were previously only available on iOS (and by default block analytics trackers) became available on Android, at least to Samsung users.
Also, this newer sample is mostly done with GA transport method: “beacon”, which in theory should also limit the amount of false positives, though I was not able to see any discernible difference after changing that method.
Update December 2017
Total GA blockers have gone down since our last experiment run in June 2016.
GA blocking percentage: 8%
Recap:
Jan 2016: 8.7%
Jun 2016: 11%
Dec 2017: 8%
This run of the experiment was similar in size to the first run (about 6 weeks, 2,220 users), so as before not a huge sample.
Changes in the blocker profiles since previous runs:
- Way more Android blocking. Android made up 68% of the blocking audience, a flip from the original experiment where iOS was predominent. Android users now appear to be more likely to be running blockers than iOS users.
- Firefox users are running more blocking. In this 2017 run Firefox users made up just 9% of the audience (same as in 2015), but 30% of the blockers, up from 19% in the first run. Two possible reasons for this may be:
- The movement of Firefox users from Adblock Plus (which does not block GA by default) to uBlock Origin (which does block GA by default). This may have also happened on other browsers, but it well-documented for Firefox because of the usage statistics they provide.
- An increase in non-EU/US blocking. Since our test site is largely US-targeted, we don’t have a lot of data on this, but this would be in line with reporting from PageFair earlier in 2017 documenting a big increase in mobile ad blocking in Asia.
So what does this mean?? Are blocking rates down?
The previously mentioned Firefox add-on stats show some changes.
Average Daily Users
| Add-on | Nov 2016 | Nov 2017 | Change |
| AdBlock Plus | 20.4M | 13.2M | -7.2M daily users |
| uBlock Origin | 2M | 4.2M | +2.2M |
| totals: | 22.4M | 17.4M | -5M |
This migration is likely due to the “acceptable ads” program which ABP participates in but uBlock Origin does not. This is a net -5M decrease in daily users of the 2 most popular Firefox content blockers, but due to both a change in how Firefox counted daily users in June 2017 where they no longer count a disabled install as an active user (and also Firefox’s decreased market share in that period) I would not take that -5M as an indicator of a decrease in ad block users overall.
My take — this represents a slowdown or even plateau in ad block growth rates overall, but the shift towards blockers that block GA by default mean that GA block rates have likely not changed much overall or perhaps even increased.
As stated throughout this article, this is one experiment on one website, not an attempt to track GA block rates across the web. These block rates are highly dependent upon the type of user, and as the type of user has changed to our test site over time the resultant block rate have also changed.
During our early 2016 experiments, the test site ranked well for some meme-related search terms that I am confident are associated with high probability blocker users. In late 2017 that traffic has shifted to more general purpose organic shopping terms. So even if the over demographic hasn’t changed, the individual users are less likely to be blockers. In all runs of the experiment that organic traffic was mixed with paid traffic from the same AdWords campaigns to try and provide as much consistency as possible, but obviously what keywords the site ranks for in organic isn’t controllable in the same way.
Looking for the code I used to run this? The basics are on github.
I used Analytics Pro’s Universal Analytics PHP library and RGoogleAnalytics in addition to the other tools already mentioned.
To protect the privacy of the users (especially those that are intentionally blocking GA) this experiment was done in a separate GA property with no ties to any other information the experiment site had about the user.
Thanks to wmacgyver for the JavaScript assistance and sanity checks.
Hmmm,
Good article, but what about finishing with a “what to do?” part? Such as hosting the analytics file in the website host to avoid tracking blocker.
Hi Cédric,
Thanks for commenting, that is a really good point. The reason why I avoided suggesting self-hosting as you describe is that it is likely against the GA terms of service. The terms say:
“You must not circumvent any privacy features (e.g., an opt-out) that are part of the Service.”
What I take that to mean is that it is against the rules to purposely break the official opt-out extension: https://tools.google.com/dlpage/gaoptout
Unfortunately with the method I describe of essentially server-side proxying the measurement requests can’t differentiate someone using the official opt-out extension vs. Ghostery, ABP, or whatever. So even though the vast majority of analytics blocking users are not opting-out via the “official” opt-out provided by Google we’re sort of stuck by that rule.
Plus I would very much like to respect the wishes of those who choose to opt-out. I’d prefer a system where those that opt-out know that they are opting out of analytics as well as ads (vs. defaulting to everything like many blockers do) and I’d also prefer that opt-out means that we are still aware of the existing of these users in GA, just that they have been thoroughly anonymized and showing a much more basic tracking profile.
I do think that for some sites a server-side analytics solution is part of the answer, but I don’t think that can be done with GA at this time.
Hi Jason,
Yes it breaks the opt-out. But from this page it seems not forbidden by google, just not recommended.
https://support.google.com/analytics/answer/1032389?hl=en
«I do think that for some sites a server-side analytics solution is part of the answer»
It sounds a great idea, but I guess limited, especially for 100% html website (I just left wordpress for a static blog generator which is giving me awesome SEO results). I am not good enough in web programming to have a good idea on that point.
«Plus I would very much like to respect the wishes of those who choose to opt-out»
Haha I have a very different point of view on that. I want to be among those who want to convince to stop those practises because most of those who does that are paranoid or manipulated guy that are trying to prove that they belong to some categories of persons. If this manipulation spread too much…this is going to go bad for us…and unfortunately most of the ad-blocker users invite others to do so to join the «smarter clan».
So at best I could warn them and invite them to blacklist my site if they don’t agree with my rules. Or to agree to take my website for the whole.
For ads, I am trying to replace adsense by amazon affiliate custom ads, that are difficult to block.
I will try and see how it performs.
What they mean on that link is just hosting the JavaScript tracker file (analytics.js) locally, which would not get around blocking because in that case it still would fire the measurement protocol requests from the end-users’ browser.
Definitely if you can get your users to whitelist your site specifically that is the best way to stop the blocking, good luck!
“which would not get around blocking because in that case it still would
fire the measurement protocol requests from the end-users”
Ok I see, thanks for this information. I guess I will work with the analytics blockers then.
“if you can get your users to whitelist”
Not possible as most of my traffic (90%) are new visitors from google. But for ads I have an adsense alternative that is not blocked by default. =) I replace adsense by dual image slider with amazon affiliate links.
I block any and all tracking/ad scripts, it’s my right to do so. Free Internet baby and no I don’t care if you don’t get paid.
Don’t like it, don’t use it, get out of here! Fair play to such a beacon of humanity as yourself though I suspect you will be completely blind to your own hypocrisy.
Very interesting. Are you planning a 2017 update?
Yes, a couple of updates are in the works. Thanks!
Hey, Jason – great article.
I came across this post when doing my own research into adblockers vs Google Analytics, and found similar results.
I’ve just published my research at https://www.tallprojects.co.uk/articles/google-analytics-is-lying-to-you/. (Includes a reference to you).
Many thanks
Thanks Edward! I read your article and appreciate the shout-out, interesting stuff.
Great information, thank you. Any plans to update for 2019? I would be very interested to see if any increases have occurred in the past 2 years.
Thank you again.
Hi Geoff,
I don’t have any plans to further update using this method, sorry.
The rate of growth in adblockers has by most reports leveled off in the last couple of years — so I expect the numbers would be similar to slightly higher. There’s been a continued trend towards grouping trackers along with ads in terms of things to block, so the analytics blocking rate has likely gone up at a slightly higher rate than just adblockers.
Because of changes in both the site I ran this experiment on and browser tech changes (specifically changes in fingerprinting) I don’t believe I could publish an update that would represent an accurate measure of how things have changed since then.
Thanks for your interest though, I may still publish more on the topic with different methods, it just wouldn’t be a continuation that could show growth over time accurately.