When Do Bots Show Up In Google Analytics?
Categories: analytics
Did you know that your site probably serves up more pages to bots than humans? Unless you’re looking at a site with a high amount of users, that ratio could be quite tilted towards bots. This isn’t a bad thing, a lot of bots are crucial to to the functioning of sites and the internet as a whole. What can be bad is when these bots mess up our analytics reports when we don’t realize they are doing so. Especially bots that masquerade as real users, or analytics reports that can’t differentiate between bots and users — that’s our real problem.
Recently I have seen a number of Google Analytics reports with spikes in traffic that ultimately turned out to be bots. The question I want to look at in this article is how much of a problem is this and what can we do about it?
How Much Bot Traffic is Out There?
This is pretty well-trod ground, so there are some pretty good numbers out there on this. Incapsula and Distil Networks are two popular bot security platforms that report on bot traffic. The two sets of numbers differ a little — but both show a lot of bot traffic out there, and especially if you have a smaller site.
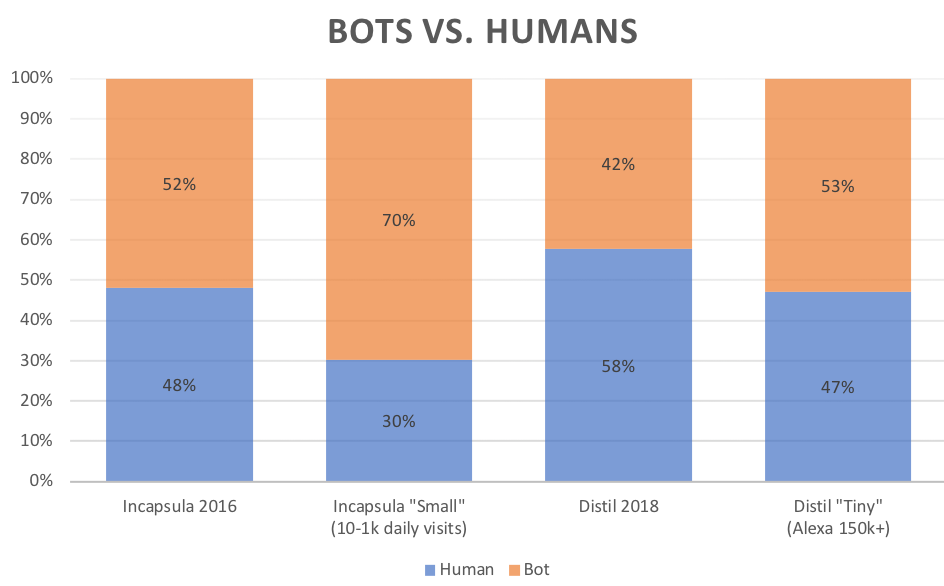
(sources: Distil Networks 2018 bad bot report, Incapsula 2016 bot traffic report)
According to Incapsula’s numbers, if you’ve got under 1k daily (human) visits you should expect to see 70% of your traffic be bots. Distil doesn’t report on sites that are quite that small, but the trend is the same — the lower your human traffic, the higher the percentage of bot traffic. For example, the site you’re on right now typically gets about 1,000 users per month. I don’t have the forensic detection ability of a Distil or Incapsula, but a simple investigation of my server logs shows about 90% of my overall traffic was bots. Mostly good bots, but bots nonetheless.
So the question is — how many of those bots end up in our Google Analytics?
When we talk about what shows up, at first we are looking at what shows up without the magic “exclude all hits from known bots and spiders” checkbox in the view setup, then later we’ll look at how that option affects things as well.
“Dumb” vs. “Smart” Bots
As far as having the capacity to show up in Google Analytics (or any other similar analytics tool), the important question is if the bot supports JavaScript and has the capacity of reading and executing the GA script. Historically that has been the main defense against bots showing up in GA — most bots just couldn’t execute the JavaScript. No filtering required, they never even fire the requests of to GA.
These “dumb” bots fetch the HTML of a page, but that’s pretty much it. For a lot of bots, that’s all they need to do. If you want to check if your homepage is up & responding, all you need to do is fetch the HTML of that page and check for a string you expect to be there.
Let’s take the case though of a fancier web app — where to really check if its working we’d need to see if it loaded and executed all the JavaScript and other page components. This puts us into the realm of the smart bots, which could be anything built upon a headless browser that executes the JavaScript and attempts to render and perhaps interact with the page.
Just like with dumb bots this smart bot could be for a benevelant purpose (like Googlebot), or it could be nefarious (like a ad fraud bot creating fake ad views). By the total number of bots a typical site sees most of them are dumb still, but things are changing. Chrome headless mode was released in June 2017 which has made smart bots a lot easier to build.
Let’s look at the logs from quantable.com! Maybe that doesn’t sound super fun, but I am a big proponent of analyzing server log data since it can contain a lot of information that GA doesn’t.
Last week showed “declared” bots as 88% of all my hits to content pages (about 15k total). By “declared” I mean bots that didn’t cloak their user agent pretending to be a real human browser, they either left their tool’s user agent in place or had their own custom user agent saying what they were.
These hits came from a wide variety of bots, 47 different user-agents. Most of the hits are ones I ordered up myself! For example user agents like Pingdom (which checks if my site is up), WordPress (which calls itself all the time for various reasons), and W3 Total Cache (which hits the site to pre-load the cache) made up over 80% of hits.
| Bot Type | Percentage of Content Hits |
| Uptime Monitor | 70.9% |
| Internal WordPress | 10.3% |
| Search Engines | 2.8% |
| RSS Readers | 2.5% |
| SEO Spiders | 1.1% |
| Unknown Scrapers | 0.7% |
| Others | 0.3% |
| All Declared Bots | 88.4% |
A full list of bot user agents ordered by volume:
Bot Name / Type Pingdom / Uptime WordPress / Internal W3 Total Cache / Internal Feed Wrangler / RSS Feedbin / RSS bingbot / Search Engine SemrushBot / SEO Barkrowler / Search Engine Googlebot / Search Engine Yandex / Search Engine Amazon CloudFront / Internal Baiduspider / Search Engine DnyzBot / Unknown Scraper null / Unknown Scraper AhrefsBot / SEO 360Spider / Search Engine linkdexbot / SEO SeznamBot / Search Engine Apache-HttpClient / Unknown Scraper Twitterbot / Other [redacted] / Spam PHP / Unknown Scraper Feedly / RSS SimplePie / RSS Reeder / RSS Cliqzbot / Search Engine Sogou / Search Engine Slackbot / Other Applebot / Search Engine Nuzzel / RSS researchscan.comsys.rwth-aachen.de / Security Scan iThemes Sync / Internal TelegramBot / Other CipaCrawler / Other pixeltodo.com / RSS noreader.com / RSS DuckDuckGo / Search Engine LivelapBot / Search Engine CCBot / Search Engine NetpeakSpiderBot / SEO Screaming Frog SEO Spider / SEO Python / Unknown Scraper Fyrebot / Unknown Scraper Mechanize / Unknown Scraper AngleSharp / Unknown Scraper G-i-g-a-b-o-t / Unknown Scraper A6-Indexer / Unknown Scraper Go-http-client / Unknown Scraper
So like I said, it’s mostly Pingdom — apparently calling your site every minute to see if it’s up adds up to a lot of hits. But there is a very long tail of unique bot user agents.
Incapsula’s 2016 report says they were tracking 504 good bots, which you can use their Botopedia to search against. I used this list: https://github.com/monperrus/crawler-user-agents of about 300 bots to check against the user agents that I thought were bots and about 60% of the ones I saw were on there, meaning there’s just a lot of bots out there that are such low volume they may not be on any list.
None of these bots showed up in Google Analytics.
That’s good right? I’d say mostly, but it does mean that a lot of site usage data that could be very helpful for SEO, security, and capacity issues ends up locked away in unexamined server logs.
As we’ve said, the reason why most of these bots haven’t shown in GA is simple — they just didn’t evaluate JavaScript. But a few did:
Bingbot, Googlebot, YandexBot, Screaming Frog, DnyzBot.
So only 5 of 48 (10.4%) of the individual bots were evaluating JavaScript. Not just downloading the associated JavaScript files linked to from the page, but actually running the JavaScript.
How can I tell they evaluated JavaScript? Loading the WordPress emojis happens from evaluated JavaScript, so only clients that evaluated JavaScript would ask for the emoji file. This is the most useful purpose of emojis in WordPress I’ve discovered so far. 😉
3 of the 5 are obviously well-known search engines. Googlebot has lead the way in evaluating JavaScript and has been able to do this for years, you can read an excellent 2015 study from Merkle about what it did render (which was basically everything). I don’t know what DnyzBot is (either does this database of bots), but it behaves pretty sketchily — not respecting robots.txt and not having a web page about the crawler. Screaming Frog is an SEO spidering tool that has the capacity to evaluate JS (though the JS functionality isn’t on by default).
All 5 of these bots could execute JS and therefore report to GA, so why didn’t they??
Either these bots are being polite/stealthy and have been coded to not fire the JavaScript, or Google filters them out automatically. My GA blocking experiment seemed to indicate these kind of bots were setup to not fire GA purposely.
It makes sense for either type of bot: if you are Googlebot, Bing, etc. you are writing something where politeness is a concern, and not firing 3rd party trackers (even if you could) seems like good practice. On the other side, if you are writing a shady scraping bot you probably also don’t want to show up in GA either so as to alert site administrators of your presence.
Let’s go back to our original question though, when do the bots show up?
In general, high profile bots that declare themselves as bots do not show up in GA.
Bots that have real browser user agents are what show up in GA. Either faked user agents or headless browsers where the user agent has not been changed from the defaults.

Next time you get a haircut, ask for the upside-down Firefox.
What Bots Do Show? Smart Bots, Headless Browsers.
As web pages have gotten much more complicated to render, the number of programs that can do a good job determining what actually shows up on a page have gotten a lot shorter. Meaning if you want your bot / program to see what the user sees, you can’t just download the plain HTML and images, you have to consider the whole DOM that is ultimately generated by the browser.
So by “headless browser”, the “headless” part means it’s being programmatically driven rather than driven by a human user, and the “browser” part means… it’s a browser.
There are a lot of ways to drive these browsers, but the browsers themselves are the same ones you’re used to — Chrome, Firefox, Safari/Webkit.
There’s plenty of legit purposes for headless browsing:
- Site testing
- Search engines
- Automating site interactions
- Screenshots
A headless browser session could be as simple as taking a screenshot from the command line like so:
$ chrome –headless –screenshot https://www.quantable.com/test-page
And that hit would show up in GA!
More likely a headless browser session is something much more complicated like a puppeteer script running some kind of automated test, or a 3rd party product. There is of course a whole category of products and services that can crawl and render your site.
I use Screaming Frog which is a great product for crawling and verifying your site, and it does indeed have the capability of fully rending a page via Chrome-based headless browsing… which we saw in our test above.
As mentioned, Screaming Frog doesn’t fire GA, and they were kind enough to tell me that they purposely chose to not load the GA code at all. They only explicitly exclude GA, so other trackers might give you a different result, but GA they don’t fire. This behavior is confirmed also in a good article here (in German) by Markus Baersch. Markus tested several spidering tools: Screaming Frog, Sitebulb, Xovi, Searchmetrics, SISTRIX and found SISTRIX to be the only one firing GA on all pages of your site. Xovi can fire GA on just your homepage, but that’s just one page.
Ok — so where are we at now?
| Bot/Browser | Fires GA? | Built-in GA bot filter works? | Declares itself with User Agent? |
| Non-JS Dumb Bots | No | n/a | Maybe. ¯\_(ツ)_/¯ |
| Chrome Headless (v59+, tested 65) | Yes (except for DOM dumps) | No | Yes |
| Firefox Headless (v56+, tested 59) | Yes (except for screenshots) | No | No |
| PhantomJS (Webkit, defunct) | Yes | Yes | Yes |
| Smart Site Crawlers (Screaming Frog, etc.) | Sometimes | Sometimes | Yes, mostly |
What can we do to remove / identify the bots?
First, we need to talk about the Bot Filtering option in GA. You know, this checkbox in the GA view settings:

If you turn that option on it will indeed block a lot of bot traffic. I recommend turning this on in all cases except those where you are using GA Measurement Protocol requests to send automated traffic into GA yourself. That is bot traffic as much as the next bot, and GA doesn’t have any whitelisting option to allow your bot and reject the others, so having that checkbox on when you are using those kind of requests can cause that to get filtered in unpredictable ways.
The built-in bot filter works firstly upon user agent exclusion based upon the IAB bots list. So if the bot in question has a user agent on that list it will get excluded, full stop. The IAB list is available by paid subscription only, but I don’t believe it is substantially different than other bot user-agent lists. It’s based on a list of user agents and substrings, not IPs or behavior. Beyond individual bots, the IAB list does appear to contain some good general rules, like stopping user agents with “bot” or “spider” in their user agent string even if that specific bot was not found (e.g. it will block “Screaming Frog SEO Spider/9.2” but not “Screaming Frog”).
As you can see in the table above though, this filter will not stop the default user agents for both Chrome and Firefox in headless mode.
So our overall flow looks like the following:

This leads to the obvious next question, is it possible to detect headless browsing?
A: Kind of, but much like bot detection in general it’s not possible to do with high degrees of confidence. The problem is that most of the easy detection methods are also easily fooled, and beyond those simple methods we enter a world of maybes… and we don’t want to exclude traffic from our analytics based on maybes. More reading on some detection methods here, and then some additional reading on why those methods don’t work here.
There’s 2 primary simple ways to detect these users:
- By user agent. By default some of these headless browsers will say they are headless, for example Google Chrome headless looks like this from my laptop: “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/65.0.3325.181 Safari/537.36″. So, pretty obvious. Except GA will still count that hit, even with the bot filter on (which seems seriously wrong).
- By ISP. If the traffic is coming from a server farm (e.g. amazonaws.com), then it could be a bot. It could also be a real human using that server farm as a proxy, but it’s mostly bots.
So if you’ve got the bot filter option on and are still getting a lot of bot traffic, or you can’t turn on the bot filter, then it’s time for some filters. I would only recommend using filters if you have a real problem with bot traffic spikes or significant data pollution though! Look for segments of users by network domain and service provider dimensions that have very high bounce rates and never complete goals to get a good idea if it is really bot traffic or not.
We can filter out #1 by adding user agent as a custom dimension in GA and then filtering based on that dimension, or via a GTM trigger.
We can filter out #2 by adding filters based on ISP. I have added this kind of filtering as an option in my (now defunct) GA Spam Filter service as “filter bot networks”, which currently excludes 18 different network domains. I also have made a segment available in the GA Solutions Gallery that shows traffic from common server farms like Amazon AWS, etc.
Finally, how much of this is happening?
It varies a lot from site to site. My site showed about 1.5% of traffic in the “bot-ish” segment I’ve shared. More than half of that went away (the percent dropped to .6%) when I turned on the built-in GA bot filter.. so I would say no need for additional filtering. A second higher traffic site I looked at showed 1% in that segment, but the built-in filter only cut it down to .9%, so it’s closer but still seems not worth it at 1%. A third site had 7% based on some automated traffic from amazonaws.com, so I added the additional filters to that view.
Overall, while this can be a serious annoyance, most of the time it can be remedied with either the built-in bot filtering or some simple additional filtering.
I would prefer a totally different model. Instead of filtering out all of this traffic I would like to see it available but only when a certain option is turned on. Similar to how a custom segment works, but something a lot more capable and dynamic.
It seems likely that as the smart bot segment grows larger and larger with our current method the “best” outcome is that we filter out more and more traffic. Bot traffic is traffic that hit your site, used your resources, and maybe even cost you money to acquire, why would we want to totally dump that data or leave it siloed off in a bunch of un-analyzed log files? Why should it be up to the bot to decide if it should fire the tracker code at all? Bot creates are being smart to explicitly exclude GA rather than rely on filtering downstream from that, but don’t we want to know when our site is getting spidered?
No comments yet.